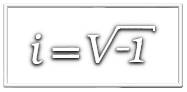Números complexos
A álgebra dos complexos
Para compreender a necessidade dos números complexos podemos considerar a solução de equações do tipo
$$
x^{2}+1=0.
$$
Para obter uma solução definimos \(\sqrt{-1}=i,\) a que damos o nome de unidade imaginária. Como consequência desta definição as raízes de (1) são \(i\) e \(-i\) pois
$$
i^{2}=\left( \sqrt{-1}\right) ^{2}=-1;\,\;\;\;\;\left( -i\right) ^{2}=-1.
$$
Um número complexo é um número na forma \(a+bi,\) possuindo, portanto, uma parte real \(a\) e uma parte imaginária \(b\). O conjunto dos complexos é
$$
\mathbb{C} =\left\{ x+iy;\;x,y\in \mathbb{R} \right\}.
$$
Um número complexo qualquer, \(z=x+iy,\) é composto de parte real e parte imaginária, respectivamente
$$
\begin{array}{ll}
\text{Re}\left( z\right) = & x, \\
\text{Im}\left( z\right) = & y.
\end{array}
$$
Dados dois complexos \(z_{1}=x_{1}+iy_{1}\;\) e \(\; z_{2}=x_{2}+iy_{2}\;\) as seguintes operações podem ser definidas:
Adição: \(z_{1}+z_{2}=\left( x_{1}+iy_{1}\right) +\left(x_{2}+iy_{2}\right) =\left( x_{1}+x_{2}\right) +i\left( y_{1}+y_{2}\right) \)Subtração: \(z_{1}-z_{2}=\left( x_{1}+iy_{1}\right) -\left(x_{2}+iy_{2}\right) =\left( x_{1}-x_{2}\right) +i\left( y_{1}-y_{2}\right) \)
Multiplicação: \(\ z_{1}\cdot z_{2}=\left( x_{1}+iy_{1}\right) \cdot\left( x_{2}+iy_{2}\right) =\left( x_{1}x_{2}-y_{1}y_{2}\right) +i\left(x_{1}y_{2}+x_{2}y_{1}\right) \)
Divisão: para \(z_{2}\) \(\neq 0:\)
$$
\frac{z_{1}}{z_{2}}=\frac{x_{1}+iy_{1}}{x_{2}+iy_{2}}=\frac{x_{1}+iy_{1}}{x_{2}+iy_{2}}\frac{x_{2}-iy_{2}}{x_{2}-iy_{2}}=\frac{\left(
x_{1}x_{2}+y_{1}y_{2}\right) +i\left( x_{2}y_{1}-x_{1}y_{2}\right) }{\left(
x_{2}\right) ^{2}+\left( y_{2}\right) ^{2}}.
$$
Observe que \(z_{1}=z_{2}\) se, e somente se, \(x_{1}=x_{2}\) e \(y_{1}=y_{2}\), de forma que uma equação complexa envolve, na verdade, duas equações reais.
Representação cartesiana e polar

O conjunto dos complexos pode ser representado por meio do plano complexo, em sua forma cartesiana, mostrada na figura 1 (a) ou polar, figura (b).
As coordenadas cartesianas e polares se relacionam da seguinte forma:
$$
\left\{
\begin{array}{ll}
x= & r\cos \theta \\
y= & r\text{sen }\theta\end{array}\right. \Rightarrow \left\{
\begin{array}{ll}
r= & \sqrt{x^{2}+y^{2}}, \\
\theta = & \arctan \left( \frac{y}{x}\right).\end{array}\right.
$$
Podemos portanto escrever \(z=x+iy\) como
$$
z=r\left( \cos \theta +i\text{sen }\theta \right) ,
$$
onde as variáveis \(\left( r, \theta \right) \) e \(\left( x, y\right)\) se relacionam de acordo com as expressões em (2).
Definições: O valor absoluto de \(z=x+iy\) é denotado por
$$
\left\vert z\right\vert =\sqrt{x^{2}+y^{2}}=r,
$$
enquanto \(\theta \) é chamado de argumento de \(z,\; \theta =\text{Arg}\left( z\right).\) O conjugado complexo de \(z\) é denotado por \(\bar{z}\) e definido como
$$
\bar{z}=x-iy.
$$

Vemos na figura 2 que \(\left\vert z\right\vert \) é a distância do ponto até a origem enquanto \(\bar{z}\) é o complexo obtido de
\(z\) por reflexão no eixo real. Observe que, em termos destas definições temos:
$$
z\bar{z}=\left\vert z\right\vert ^{2},
$$
enquanto a divisão entre complexos pode ser escrita como
$$
\frac{z_{1}}{z_{2}}=\frac{z_{1}\bar{z}_{2}}{z_{2}\bar{z}_{2}}=\frac{z_{1}\bar{z}_{2}}{\left\vert z_{2}\right\vert ^{2}}.
$$
Exercícios Resolvidos:
(1) Encontre as partes reais e imaginárias dos números complexos:
$$
z_{1}=\frac{1-i\sqrt{2}}{\sqrt{2}+i};\ \;\;\;\;\;\ z_{2}=\left( 1+i\right)^{8}.
$$
Racionalizamos o primeiro:
$$
z_{1}=\frac{1-i\sqrt{2}}{\sqrt{2}+i}\frac{\sqrt{2}-i}{\sqrt{2}-i}=\frac{\sqrt{2}-i-2i-\sqrt{2}}{3}=-i,
$$
e o segundo
$$
z_{2}=\left( 1+i\right) ^{8}=\left[ \left( 1+i\right) ^{2}\right]^{4}=\left( 2i\right) ^{4}=2^{4}=16.
$$
Portanto \(\text{Re}\left( z_{1}\right) =0,\;\text{Im}\left( z_{1}\right)=-1;\;\text{Re}\left( z_{2}\right) =16,\;\text{Im}\left( z_{2}\right) =0.\)
(2) Escreva na sua forma polar e calcule os conjugados complexos de:
$$
z_{3}=i,\;\;z_{4}=\frac{i}{1-i}.
$$
O argumento de \(z_{3}\;\) pode ser visto apenas pela posição do ponto no plano complexo, \(\theta =\pi /2,\,\) enquanto seu valor absoluto é \(\left\vert z_{3}\right\vert =\sqrt{1^{2}+0}=1.\) Então
$$
z_{3}=i=\cos \frac{\pi }{2}+i\;\text{sen }\frac{\pi }{2},
$$
$$
\bar{z}_{3}=\bar{\imath}=-i\;\;\text{ ou }\;\;\bar{z}_{3}=\cos \frac{\pi }{2}-i\;\text{sen }\frac{\pi }{2}.
$$
Quanto a \(z_{4}\;\) é melhor racionalizá-lo antes
$$
z_{4}=\frac{i}{1-i}\frac{1+i}{1+i}=\frac{-1+i}{2}.
$$
Portanto \(x=-\frac{1}{2}\) e \(y=\frac{1}{2}\) e
$$
r=\sqrt{\left( \frac{1}{2}\right) ^{2}+\left( \frac{1}{2}\right) ^{2}}=\frac{1}{\sqrt{2}}=\frac{\sqrt{2}}{2},
$$
$$
\theta =\arctan \left( -1\right) =\frac{3\pi }{4}.
$$
Observe que \(\tan \left( 3\pi /4\right) =\tan \left( 7\pi /4\right) =-1.\) Sabemos no entanto que \(\theta =3\pi /4\) porque \(z_{4}\) está no segundo quadrante. Seu complexo conjugado é:
$$
z_{4}=\frac{-1-i}{2}
$$
Produto e quociente na forma polar
Algumas operações são mais simples se os números dados estão na forma cartesiana, como ocorre na adição. Outras poderão ser muito simplificadas se escrevermos os termos envolvidos em forma polar. Dados
$$
z_{1}=r_{1}\left( \cos \theta _{1}+i\text{sen }\theta _{1}\right) \;\;\text{ e }\;\;z_{2}=r_{2}\left( \cos \theta _{2}+i\text{sen }\theta_{2}\right)
$$
encontramos o produto:
$$
z_{1}z_{2}=r_{1}r_{2}\left( \cos \theta _{1}+i\text{sen }\theta _{1}\right)\left( \cos \theta _{2}+i\text{sen }\theta _{2}\right) =
$$
$$
r_{1}r_{2} \left[ \cos \theta _{1}\cos \theta _{2}-\text{sen }\theta _{1}\text{sen }\theta _{2}+i\left( \cos \theta _{1}\text{sen }\theta _{2}+\text{sen }\theta _{1}\cos \theta _{2}\right) \right].
$$
Usando as identidades trigonométricas:
$$\begin{array}{l}
\cos A\cos B-\text{sen }A\text{sen }B=\cos \left( A+B\right), \\
\cos A\text{sen }B+\text{sen }A\cos B=\text{sen }\left( A+B\right),
\end{array}
$$
obtemos
$$
z_{1}z_{2}=r_{1}r_{2}\left[ \cos \left( \theta _{1}+\theta _{2}\right) +i\text{sen }\left( \theta _{1}+\theta _{2}\right) \right] .
$$
Isto significa que, para multiplicar dois complexos, multiplicamos seus valores absolutos e somamos seus argumentos. Para efetuar a divisão observe antes que
$$
\frac{1}{\cos \theta _{1}+i\text{sen }\theta _{1}}=\frac{1}{\cos \theta _{1}+i\text{sen }\theta _{1}}\frac{\cos \theta _{1}-i\text{sen }\theta _{1}}{\cos\theta _{1}-i\text{sen }\theta _{1}}=\cos \theta _{1}-i\text{sen }\theta _{1},
$$
já que o denominador é \(\cos ^{2}\theta _{1}+\text{sen }^{2}\theta_{1}=1.\) Temos então que, se \(z_{2}\neq 0,\)
$$
\frac{z_{1}}{z_{2}}=\frac{r_{1}\left( \cos \theta _{1}+i\text{sen }\theta_{1}\right) }{r_{2}\left( \cos \theta _{2}+i\text{sen }\theta _{2}\right) }=\frac{r_{1}}{r_{2}}\left( \cos \theta _{1}+i\text{sen }\theta _{1}\right)\left( \cos \theta _{2}-i\text{sen }\theta _{2}\right) =
$$
$$
\frac{r_{1}}{r_{2}}\left[ \cos \left( \theta _{1}-\theta _{2}\right) +i\text{sen }\left( \theta _{1}-\theta _{2}\right) \right] .
$$
Fórmulas de de Moivre e de Euler
Considere \(n\) números complexos, expressos por
$$
z_{k}=r_{k}\left( \cos \theta _{k}+i\text{sen }\theta _{k}\right),\;\; k=1,..n.
$$
Para multiplicar todos estes números podemos operar dois a dois até incluir os \(n\) números, obtendo
$$
z_{1}z_{2}\ldots z_{n}=r_{1}r_{2}\ldots r_{n} \left[ \cos \left( \theta
_{1}+\theta _{2}+\ldots +\theta _{n}\right) +i\text{sen }\left( \theta
_{1}+\theta _{2}+\ldots +\theta _{n}\right) \right] .
$$
Se todos os \(n\) fatores são iguais temos
$$
z\;\; z\ldots z=z^{n}=r^{n}\left( \cos n\theta +i\text{sen }n\theta \right).
$$
Se \(\left\vert z\right\vert =1\) então \(r=1\) e obtemos a fórmula de de Moivre:
$$
\left( \cos \theta +i\text{sen }\theta \right)^{n}=\left( \cos n\theta +i\text{sen }n\theta \right).
$$
Observe que a fórmula acima vale também para expoentes negativos, pois
$$
\left( \cos \theta +i\text{sen }\theta \right) ^{-n}=\frac{1}{\cos n\theta +i\text{sen }n\theta }=\cos n\theta -i\text{sen }n\theta .
$$
Usando o fato de que o cosseno é par e o seno é ímpar, ou seja,
$$
\cos \left( -\theta \right) =\cos \theta;\;\;\text{sen }\left( -\theta\right) =-\text{sen }\theta,
$$
podemos escrever
$$
\left( \cos \theta +i\text{sen }\theta \right) ^{-n}=\cos \left( -n\theta\right) +i\text{sen }\left( -n\theta \right).
$$
Outra expressão importante foi obtida por Euler da seguinte forma: partimos das expansões em séries de potências para as funções exponencial, seno e cosseno, respectivamente
$$
e^{x}=1+x+\frac{x^{2}}{2!}+\frac{x^{3}}{3!}+\cdots +\frac{x^{n}}{n!}+\cdots ,
$$
$$
\text{sen }x=x-\frac{x^{3}}{3!}+\frac{x^{5}}{5!}-\frac{x^{7}}{7!}+\cdots
$$
$$
\cos x=1-\frac{x^{2}}{2!}+\frac{x^{4}}{4!}-\frac{x^{6}}{6!}+\cdots.
$$
Fazendo \(x=i\theta \) no argumento da exponencial obtemos
$$
e^{i\theta }=1+i\theta +\frac{\left( i\theta \right) ^{2}}{2!}+\frac{\left(i\theta \right) ^{3}}{3!}+\cdots +\frac{\left( i\theta \right) ^{n}}{n!}+\cdots =
$$
$$
=1+i\theta -\frac{\theta ^{2}}{2!}-\frac{i\theta ^{3}}{3!}+\frac{\theta ^{4}}{4!}+\frac{i\theta ^{5}}{5!}-\cdots.
$$
Agrupando os termos reais e imaginários temos
$$
e^{i\theta }=1-\frac{\theta ^{2}}{2!}+\frac{\theta ^{4}}{4!}-\cdots +i\left(
\theta -\frac{\theta ^{3}}{3!}+\frac{\theta ^{5}}{5!}-\cdots \right).
$$
Podemos agora identificar a parte real com o cosseno e a parte imaginária com o seno e, portanto,
$$
e^{i\theta }=\cos \theta +i\text{sen }\theta.
$$
Ela nos permite escrever números complexos em uma forma alternativa, muito útil para a realização de diversas operações,
$$
z=x+iy=r\left( \cos \theta +i\text{sen }\theta \right) =re^{i\theta }.
$$
Observe que, nesta representação, o complexo conjugado é
$$
\bar{z}=r\left( \cos \theta -i\text{sen }\theta \right) =re^{-i\theta },
$$
onde usamos a paridade das funções trigonométricas, descrita nas equações (3).
A multiplicação e divisão dos complexos se torna bem mais simples se eles estão escritos em sua forma exponencial. Se \(z_{1}=r_{1}e^{i\theta _{1}}\) e \(z_{2}=r_{2}e^{i\theta _{2}}\) então
$$
z_{1}z_{2}=\left( r_{1}e^{i\theta _{1}}\right) \left( r_{2}e^{i\theta
_{2}}\right) =r_{1}r_{2}e^{i\left( \theta _{1}+\theta _{2}\right) },
$$
$$
\frac{z_{1}}{z_{2}}=\frac{r_{1}e^{i\theta _{1}}}{r_{2}e^{i\theta _{2}}}=\frac{r_{1}}{r_{2}}e^{i\left( \theta _{1}-\theta _{2}\right) }.
$$
Igualmente
$$
z^{n}=\left( re^{i\theta }\right) ^{n}=r^{n}e^{in\theta },
$$
$$
z^{-n}=\frac{1}{r^{n}}e^{-in\theta }.
$$
Extração de raízes
Dados dois números complexos, \(z,\,p\in \mathbb{C}\) dizemos que \(z\) é a raíz enésima de \(p,\) \(z=\sqrt[n\,]{p},\) se \(z^{n}=p.\) Tomando \(p=r\left( \cos \theta +i\text{sen }\theta \right) \) então
$$
z=\sqrt[n\,]{p}=\sqrt[n\,]{r}\left[ \cos \left( \frac{\theta +2k\pi }{n}\right) +i\text{sen }\left( \frac{\theta +2k\pi }{n}\right) \right] ,
$$
\(k=0,1,\cdots ,n-1.\) Isto está correto porque
$$
z^{n}=r\left[ \cos \left( \theta +2k\pi \right) +i\text{sen }\left( \theta
+2k\pi \right) \right] =r\left[ \cos \theta +i\text{sen }\theta \right] =p,
$$
uma vez que o seno e o cosseno são funções periódicas de período \(2\pi .\) Temos portanto \(n\) raízes distintas,
$$
z_{k}=\sqrt[n\,]{r}\left[ \cos \left( \frac{\theta +2k\pi }{n}\right) +i\text{sen }\left( \frac{\theta +2k\pi }{n}\right) \right].
$$
Observe que se fizermos \(k=n\) então
$$
z_{n}=\sqrt[n\,]{r}\left[ \cos \left( \frac{\theta }{n}+2\pi \right) +i\text{sen }\left( \frac{\theta }{n}+2\pi \right) \right] =z_{0},
$$
ou seja, retornamos à raiz correspondente à \(k=0.\) Existem portanto \(n\) raízes \(n\)-ésimas distintas de um número complexo qualquer \(p\neq 0.\)
Exercício Resolvido: Calcule as raízes n-ésimas de 1.
Primeiro representamos \(1\) em sua forma polar, correspondendo à \(r=1,\,\theta =0.\) Logo \(1=\cos 0+i\text{sen }0.\) Agora podemos extrair as raizes
$$
w_{k}=\cos \frac{2k\pi }{n}+i\text{sen }\frac{2k\pi }{n}.
$$
Observe que, se denotarmos
$$
w=\cos \frac{2\pi }{n}+i\text{sen }\frac{2\pi }{n},
$$
podemos representar as demais raízes por meio da fórmula de de Moivre,
$$
w^{k}=\cos \left( \frac{2k\pi }{n}\right) +i\text{sen }\left( \frac{2k\pi
}{n}\right).
$$
Estas são as chamadas raízes da unidade, \(w=\sqrt[n\,]{1},\) dadas por:
$$
1,w,w^{2},\ldots ,w^{n-1}.
$$
Exercício Resolvido: Vamos encontrar as raízes quartas de da unidade, \(\sqrt[4\,]{1}\), um caso particular do exercício anterior. Estas raízes são \(1,\;w,\;w^{2},\;w^{3}\) onde
$$
w=\cos \frac{\pi }{2}+i\text{sen }\frac{\pi }{2}=i.
$$
As demais raízes são
$$
w^{2}=i^{2}=-1,\;\;\;\;\;\text{ e }\;\;\;\;w^{3}=i^{3}=-i.
$$
As raízes são, portanto: \(1,\) \(i\), \(-1,\;-i.\)
Observe que a fórmula (4) para as raízes de um número qualquer pode ser escrita como
$$
z_{k}=\sqrt[n\,]{r}\left( \cos \frac{\theta }{n}+i\text{sen }\frac{\theta
}{n}\right) \left( \cos \frac{2k\pi }{n}+i\text{sen }\frac{2k\pi }{n}\right) =\sqrt[n\,]{r}\left( \cos \frac{\theta }{n}+i\text{sen }\frac{\theta }{n}\right) w^{k}.
$$
As raízes de um número \(z\) qualquer são dadas pelo produto de uma de suas raízes com as raízes \(n-\) ésimas da unidade.
Exercício Resolvido: Calcule as raízes \(\sqrt[3\,]{27}.\)
Uma das raízes é \(3.\) As raízes cúbicas da unidade são \(1,\;w,\;\; w^{3},\) onde
$$
w=\cos \frac{2\pi }{3}+i\text{sen }\frac{2\pi }{3}=-\frac{1}{2}+i\frac{\sqrt{3}}{2}.
$$

As raízes são, portanto, \(z_{0}=3,\)
$$
z_{1}=3\left( \cos \frac{2\pi }{3}+i\text{sen }\frac{2\pi }{3}\right) =-\frac{3}{2}+i\frac{3\sqrt{3}}{2},
$$
$$
z_{2}=3\left( \cos \frac{4\pi }{3}+i\text{sen }\frac{4\pi }{3}\right) =-\frac{3}{2}-i\frac{3\sqrt{3}}{2}.
$$
As três raízes estão sobre um círculo de raio \(3\) e são representadas graficamente na figura.
Exercício Resolvido: Calcule as raízes cúbicas de \(-1\) e as represente graficamente no plano complexo. Começamos por escrever em forma polar:
$$
\sqrt[3]{-1}=\sqrt[3]{\cos \pi +i\text{sen }\pi }.
$$
Sabemos que temos três raíz:
$$
z_{k}=\cos \frac{\pi +2k\pi }{3}+i\text{sen }\frac{\pi +2k\pi }{3},\;\;k=0,1,2.
$$
Portanto
$$
z_{0}=\cos \frac{\pi }{3}+i\text{sen }\frac{\pi }{3}=\frac{1}{2}\left( 1+i\sqrt{3}\right) ,
$$
$$
z_{1}=\cos \pi +i\text{sen }\pi =-1,
$$
$$
z_{2}=\cos \frac{5\pi }{3}+i\text{sen }\frac{5\pi }{3}=\frac{1}{2}\left(
1-i\sqrt{3}\right).
$$
Note que, se fizermos \(k=3\) obteremos novamente a raiz \(z_{0}.\)
Exercício Resolvido: Calcule as raízes \(\sqrt{-i}\). Observe que
$$
\sqrt{-i}=\sqrt{\cos 3\pi /2+i\text{sen }3\pi /2}.
$$
As duas raízes são, portanto:
$$
z_{k}=\cos \left( \frac{3\pi }{4}+k\pi \right) +i\text{sen }\left( \frac{3\pi }{4}+k\pi \right) ,\;\;k=0,1,
$$
ou seja
$$
z_{0}=\cos \frac{3\pi }{4}+i\text{sen }\frac{3\pi }{4}=\frac{\sqrt{2}}{2}\left( -1+i\right) ,
$$
$$
z_{1}=\cos \frac{7\pi }{4}+i\text{sen }\frac{7\pi }{4}=\frac{\sqrt{2}}{2}\left( 1-i\right) ,
$$
 Representamos graficamente as raízes obtidas nos dois exercícios na figura.
Representamos graficamente as raízes obtidas nos dois exercícios na figura.
Exercício Resolvido: Decomponha o polinômio \(P\left( z\right)=z^{3}+1\) em um produto de fatores do \(1\)º grau. As raízes de \(P\left( z\right) \) já foram encontradas no problema 2(a). Usando o teorema fundamental da álgebra temos
$$
P\left( z\right) =\left( z-z_{0}\right) \left( z-z_{1}\right) \left(z-z_{2}\right)
$$
ou seja
$$
P\left( z\right) =\left( z+1\right) \left( z-\frac{1}{2}-\frac{i\sqrt{3}}{2}\right) \left( z-\frac{1}{2}+\frac{i\sqrt{3}}{2}\right).
$$
Subconjuntos de \(\mathbb{C}\)
Algumas definições são necessárias para a continuidade de nosso estudo e a solução dos próximos exercícios. Façamos uma lista destas definições:

- Um disco aberto é a região
$$
D_r \left( z_0 \right) =\left\{ z;\;\left\vert z-z_{0}\right\vert \lt r \right\},
$$
representada graficamente na figura seguinte. - Uma vizinhança de \(z_{0},\) que denotaremos por \(V_{r}\left( z_{0}\right) \) é qualquer subconjunto de \(\mathbb{C}\) que contenha \(D_{r}\left( z_{0}\right).\)
- Dado um conjunto de \(C\subset \mathbb{C}\) chamaremos de seu complementar o conjunto \(C^{\prime }= \mathbb{C} – C,\) o conjunto dos pontos do plano complexo que não estão em \(C.\)
- Um ponto \(z_{0}\) qualquer é dito um ponto interior de \(C\) se existe um disco aberto centrado em \(z_{0}\) inteiramente contido em \(C.\)
- Um conjunto é aberto se todos os seus pontos são pontos interiores. Um conjunto é fechado se seu complementar é aberto.
- A fronteira de \(C\) é o conjunto de pontos \(z\) tais que qualquer vizinhança de \(z\) contém pontos de \(C\) e de seu complementar.
- Nenhum ponto interior de um conjunto é um ponto de fronteira.
- \(C\) é aberto \(\Leftrightarrow C\) não contém pontos de sua fronteira.
- \(C\) é fechado \(\Leftrightarrow C\) contém todos os pontos de sua fronteira.
- \(z_{0}\) é um ponto de acumulação de \(C\) se qualquer vizinhança de \(z_{0}\) contém infinitos ponto de \(C.\) Portanto, pontos do interior e pontos da fronteira, pertencendo ou não a \(C,\) são pontos de acumulação.
- Um ponto isolado de \(C\) é um ponto de \(C\) que não é ponto de acumulação.
- Um aberto \(C\) é conexo se dois quaisquer de seus pontos podem ser unidos por um arco inteiramente contido em \(C.\)
- Uma região é um conjunto aberto e conexo.
- \(C\) é limitado se existe um número \(k\) positivo tal que \(\left\vert z\right\vert \leq k,\) \(\forall z\in C.\) Um conjunto limitado e fechado é dito compacto.
- No conjunto
$$
V_{k}=\left\{ z\in C\ ;\ \left\vert z\right\vert >k\right\}
$$
incorporamos o infinito (um único ponto!) para formar o chamado plano complexo extendido.
Exemplo: No conjunto infinito
$$
C=\left\{ 0,\ \frac{1}{2},\ \frac{2}{3},\ \frac{3}{4},\ldots ,\frac{n}{n+1},\ldots \right\}
$$
\(1\) é o único ponto de acumulação, sendo todos os outros pontos isolados. Note que este único ponto de acumulção não está contido em \(C.\)

Exemplo: Vamos discutir com mais detalhes o conjunto
$$
D_r \left( z_0\right) =\left\{ z;\;\left\vert z-z_{0}\right\vert \lt r \right\}.
$$
Se denotarmos \(z=x+iy\;\) e \(\;z_{0}=x_{0}+iy_{0}\) então
$$\left\vert z-z_{0}\right\vert =\sqrt{\left( x-x_{0}\right) ^{2}+\left( y-y_{0}\right)^{2}}.$$
Portanto os pontos de \(D_r\left(z_0\right)\) satisfazem a relação
$$ \left( x-x_0\right)^{2}+\left(y-y_0\right)^{2} \lt r^{2},$$
ou seja, são os pontos interiores ao círculo de raio \(r\) e centro em \(z_0\).
Exemplo: \(\left\vert z-3i\right\vert \lt 5\) é o disco aberto interior ao círculo de raio 5 e centro em \(3i\), como na figura (a). O conjunto \(z=z_0+re^{i\theta }, 0 \leq \theta \leq 2\pi\) é a circunferência de centro em \(z_{0}\) e raio \(r\).

Exemplo: Qual é o conjunto \(\text{Re}\left(z^{2}\right) \lt 0\)? Observamos primeiro que
$$
\text{Re}\left( z^{2}\right) =\text{Re}\left( r^{2}e^{2i\theta }\right) =r^{2}\cos 2\theta .
$$
O cosseno \(\cos 2\theta\) é negativo em duas situações: \(\pi /2 \lt 2\theta \,\lt 3\pi /2 \;\;\text{ou}\;\; -3\pi /2\lt 2\theta \, \lt -\pi /2.\) O conjunto procurado é a parte do plano complexo dado por
$$
\frac{\pi }{4}<\theta \,\lt \frac{3\pi }{4}\;\; \text{ ou }\;\;\frac{-3\pi }{4}\lt \theta \,\lt \frac{-\pi }{4},
$$
as retas bissetrizes excluídas, como representado na figura.

Exercícios
1. Dados \(z_1 =\left( 3+5i\right)\;\;\text{ e } \;\; z_{2}=\left( -2+i\right)\) calcule \(z_{1}+z_{2},\;\; z_{1}-z_{2},\; z_{1}.z_{2},\; z_{1}/z_{2}.\) Represente graficamente cada um dos números complexos envolvidos.
2. Calcule:
$$
\begin{array}{llll}
\text{(a)}\frac{1}{2+3i}\ \ \ \ \ & \text{(b)}\frac{1+i}{1-i} & \text{(c)} \frac{1-i}{1+i} & \text{(d)} \frac{4-3i}{i-1} \\
\text{(e)}\frac{1}{\left( 1+i\right) ^{2}} & \text{(f)}\ \left( \frac{1+i}{1-i}\right)^{30} & \text{(g)}\ \left( 1-i\right)
\left(\sqrt{3}+i\right). &
\end{array}
$$
3. Mostre que
a.
$$
\sum\limits_{n=0}^{N}i^{n}=\left\{
\begin{array}{ll}
1, & \;\;\text{ se }\;\;r=0, \\
1+i, & \;\;\text{ se }\;\;r=1, \\
i, & \;\;\text{ se }\;\;r=2, \\
0, & \;\;\text{ se }\;\;r=3,
\end{array}\right.
$$
onde \(r\) é o resto da divisão de \(N\) por 4 seja, \(N\equiv r\text{ mod }4.\)
b. \(\left( x+iy\right) ^{2}=x^{2}-y^{2}+2ixy\)
c. \(\left( x-iy\right) ^{2}=x^{2}-y^{2}-2ixy\)
d. \(\left( x+iy\right) ^{2}\left( x-iy\right) ^{2}=\left(x^{2}+y^{2}\right) ^{2}\)
e. \(\left( x+iy\right) ^{n}\left( x-iy\right) ^{n}=\left(x^{2}+y^{2}\right) ^{n}\)
4. Mostre que
a. \(\text{Re}\left[ -i\left( 2-3i\right) ^{2}\right] =-12\)
b. \(\frac{1-i\sqrt{2}}{\sqrt{2}+i}=-i\)
c. \(\text{Im}\left[ \frac{\left( 1-i\sqrt{3}\right) ^{2}}{i-2}\right] =\frac{2}{5}\left( 1+2\sqrt{3}\right) \)
d. \(\frac{1+i\tan \theta }{1-i\tan \theta }=\cos 2\theta +i\text{sen }2\theta \)
5. Escreva na forma polar e represente graficamente:
$$
\begin{array}{llll}
\text{(a) }-2+2i & \text{(b) }1+i\sqrt{3} & \text{(c)} -\sqrt{3}+i & \text{(d)} \left( \frac{i}{1+i}\right) ^{5} \\
\text{(e) }\frac{1}{-1-i\sqrt{3}} & \text{(f)} -1-i & \text{(g)} \frac{-3+3i}{1+i\sqrt{3}}.&
\end{array}
$$
6. Mostre que \(\cos 3\theta =\cos ^{3}\theta -3\cos \theta \text{sen }^{2}\theta \;\; \text{ e } \text{sen }3\theta =-\text{sen }^{3}\theta +3\cos^{2}\theta \text{sen }\theta.\)
Sugestão: calcule as partes real e imaginária de \(\left( \cos\theta +i\text{sen }\theta \right)^{3}.\)
7. Mostre que: a. \(\left\vert \frac{2+i}{2-i\sqrt{3}}\right\vert =\frac{5}{7}\;\;\;\) b. \(\left\vert \frac{\left( \sqrt{3}+i\right)\left( 1-3i\right) }{\sqrt{5}}\right\vert =2\sqrt{2}.\)
8. Encontre as seguintes raízes e represente-as graficamente:
$$
\begin{array}{llll}
\text{(a) } \sqrt[3]{-1} \;\;\;\; & \text{(b) }\sqrt{2i} & \text{(c) } \sqrt{-2i} & \text{(d) } \sqrt[3]{i} \\
\text{(e) } \sqrt[3]{-i} & \text{(f) } \left( -1+i\sqrt{3}\right) ^{1/4}.& &
\end{array}
$$
9. Decomponha os polinômios em fatores do \(2\)º grau com coeficientes reais:
a. \(P\left( x\right) =x^{4}+1\;\;\;\;\) b. \(P\left( x\right) =x^{4}+9\)
10. Decomponha os polinômios em um produto de fatores do primeiro grau:
a. \(P(z)=z^{6}-64 \)
b. \(P(z)=z^{6}+64\)
c. \(P(z)=z^{4}-\left( 1-i\right) z^{2}-i.\)
11. Mostre que, se \(w\) é uma raíz \(n\)-ésima qualquer da unidade diferente de 1 (\(w=\sqrt{1},\) \(w\neq 1\) ) então
a. \(1+w+w^{2}+\ldots + w^{n-1}=0.\)
b. \(1+2w+3w^{2}+\ldots + nw^{n-1}=\frac{n}{w-1}.\)
12. Escreva na forma exponencial, \(z=re^{i\theta }\):
a. \(1+i,\;\;\;\) b. \(1-i,\;\;\;\) c. \(-1+i,\;\;\;\) d. \(-1-i\).
13. Mostre que:
$$
\begin{array}{ll}
\text{(a)} \exp \left( 3+7\pi i\right) =-e^{3} & \text{(b)} \exp \left( \frac{3-2\pi i}{6}\right) =\frac{\sqrt{e}\left( 1-i\sqrt{3}\right) }{2} \\
\text{(c)} \cos \theta =\frac{e^{i\theta }+e^{-i\theta }}{2} & \text{(d)}\ \text{sen }\theta =\frac{e^{i\theta }-e^{-i\theta }}{2i}
\end{array}
$$
14. Represente graficamente os conjuntos no plano complexo:
$$
\begin{array}{llll}
\text{(a) }\text{Re}\left( z\right) <-3 & \text{(b) }\left\vert z-2i\right\vert >2 & \text{(c) }\left\vert z+1\right\vert \leq 2 & \text{(d) }\left\vert z-1+i\right\vert \lt 3 \\
\text{(e) }\text{Im}\left( z^{2}\right) \lt 0 & \text{(f) }\left\vert
z-2\right\vert =\left\vert z-3i\right\vert & \text{(g) }\left\vert
z\right\vert \gt 2, \left\vert \arg \left( z\right) \right\vert <\pi
& \text{(h) }\text{Re}\left( 1-z\right) =\left\vert z\right\vert.
\end{array}
$$
Algumas Soluções
3a. Queremos mostrar que
$$
\sum\limits_{n=0}^{N}i^{n}=\left\{
\begin{array}{ll}
1, & \text{ se }\;\;r=0, \\
1+i, & \;\;\text{ se }\;\;r=1, \\
i, & \;\;\text{ se }\;\;r=2, \\
0, & \;\;\text{ se }\;\;r=3,
\end{array}
\right.
$$
onde \(r\) é o resto da divisão de \(N\) por 4 seja, \(N\equiv r\text{ mod }4\). Denotando \(N=4p+r\) observamos que
$$ i^{N}=i^{4p+r}=i^{4p}\ i^{r}=i^{r} $$
pois \(i^{4p}= (i^4)^p=1\). Este resultado é válido inclusive se \(N \lt 4\) quando \(p=0\). Vamos escrever a soma procurada como
$$ S_{N}=\sum\limits_{n=0}^{N}i^{n}=1+i+i^{2}+\ldots +i^{N} $$
e, portanto,
$$ iS_{N}=\sum\limits_{n=0}^{N}i^{n+1}=i+i^{2}+i^{3}+\ldots +i^{N+1}. $$
Subtraindo
$$ S_{N}-iS_{N}=S_{N}\left( 1-i\right) =1-i^{N+1} $$
temos uma expressão adicional para a soma procurada, ou seja
$$ S_{N}=\frac{1-i^{N+1}}{1-i}=\frac{1-i^{r+1}}{1-i}=S_{r} $$
onde a última igualdade é devida à expressão (4). Isto significa que somar os \(N\) termos equivale a somar os \(r\) primeiros termos:
$$
\begin{array}{l}
S_{0}=\sum\limits_{n=0}^{0}i^{n}=1, \\
S_{1}=\sum\limits_{n=0}^{1}i^{n}=1+i, \\
S_{2}=\sum\limits_{n=0}^{2}i^{n}=1+i+i^{2}=i, \\
S_{3}=\sum\limits_{n=0}^{3}i^{n}=1+i+i^{2}+i^{3}=0.
\end{array}
$$
Veremos que um procedimento semelhante facilitará a solução das questões 11a e 11b.
3e. \(\left(x+iy\right)^{n}\left(x-iy\right)^{n}=z^{n}\bar{z}^{n}=\left(z\bar{z}\right)^{n}=\left(\left\vert z\right\vert ^{2}\right)^{n}=\left(x^{2}+y^{2}\right)^{n}.\)
9a. Para decompor o polinômio \(P\left( x\right) =x^{4}+1\) em fatores do \(2\)º grau com coeficientes reais usaremos o produto notável \(\left( a+b\right) \left( a-b\right) =a^{2}-b^{2}.\) Escrevemos \(1=-i^{2}\) e assim
$$ P\left( x\right) =x^{4}-i^{2}=\left( x^{2}+i\right) \left( x^{2}-i\right). $$
Os dois fatores, no entanto, contém coeficientes complexos. Para obter a decomposição com coeficientes reais podemos usar a raíz de \(i\):
$$i=w^{2}\Rightarrow w=\frac{1+i}{\sqrt{2}}.$$
Tomando o conjugado complexo de \(i=w^{2}\) obtemos \(-i=\bar{w}^{2}\) e reescrevemos o polinômio
$$
P\left( x\right) =\left( x^{2}-\bar{w}^{2}\right) \left( x^{2}-w^{2}\right)=\left( x+\bar{w}\right) \left( x-\bar{w}\right) \left( x+w\right) \left(x-w\right).
$$
Reagrupando os termos de forma conveniente temos
$$
\begin{array}{rl}
P\left(x\right) = & \left[ \left( x+w\right) \left( x+\bar{w}\right) \right] \left[ \left( x-w\right) \left( x-\bar{w}\right) \right] = \\
= & \left( x^{2}+\bar{w}x+wx+w\bar{w}\right) \left( x^{2}-wx-\bar{w}x+w\bar{w}\right).
\end{array}
$$
Usamos agora as seguintes propriedades
$$w+\bar{w}=2\text{Re}\,w=\frac{2}{\sqrt{2}}=\sqrt{2}$$
$$w\bar{w}=\left\vert w\right\vert ^{2}=\left( \frac{1}{\sqrt{2}}\right)^{2}+\left( \frac{1}{\sqrt{2}}\right) ^{2}=1,$$
podemos completar o exercício:
$$P\left( x\right) =\left( x^{2}+\sqrt{2}x+1\right) \left( x^{2}-\sqrt{2}x+1\right).$$
11. Sendo \(w\) uma raíz \(n\)-ésima qualquer da unidade diferente de 1 (\(w=\sqrt{1},\;\;w\neq 1\)) então:
(a) \(1+w+w^{2}+\ldots +w^{n-1}=0.\) Escrevemos
$$ L=1+w+w^{2}+\ldots +w^{n-2}+w^{n-1} $$
$$ wL=w+w^{2}+\ldots +w^{n}=w+w^{2}+\ldots +w^{n-1}+1, $$
onde usamos \(w^{n}=1\). Observemos acima que \(wL=L\) donde
$$ wL-L = L\left(w-1\right) =0. $$
Como \(w\neq 1\) concluímos que \(L=0.\)
(b) \(1+2w+3w^{2}+\ldots + nw^{n-1}=\frac{n}{w-1}.\) Definimos
$$ S=1+2w+3w^{2}+\ldots +nw^{n-1}, $$
portanto
$$ wS=w+2w^{2}+3w^{3}+\ldots +nw^{n}=w+2w^{2}+3w^{3}+\ldots +n. $$
Dai
$$ S \left( 1-w\right) =1+w+w^{2}+\ldots + w^{n-1}-n. $$
Usando o resultado do ítem anterior \(1+w+w^{2}+\ldots + w^{n-1}=0\) e
$$ S=\frac{n}{w-1}.$$
(13a) \(\exp \left( 3+7\pi i\right) =e^{3}e^{7\pi i}=-e^{3}.\) Observe que \(e^{7\pi i}=e^{6\pi i}e^{\pi i}=\) \(-1.\)
(14h) Buscamos conjunto no plano complexo satisfazendo \(\text{Re}\left(1-z\right) =\left\vert z\right\vert .\) Escrevendo em forma cartesiana
$$ z=x+iy, z-1=x-1+iy. $$
Sua parte real é
$$ \text{Re}\left(1-z\right) =x-1 \;\; \text{ e } \text{Re}\left(1-z\right) =\left\vert z\right\vert \Rightarrow x-1=\sqrt{x^{2}+y^{2}}. $$
Elevando os dois lados ao quadrado temos
$$ x^{2}+y^{2}=\left( x-1\right) ^{2}=1-2x+x^{2} $$
que é a parábola
$$ x=\frac{1}{2}\left( 1-y^{2}\right). $$


 Em 1545 Gerônimo Cardano publicou uma fórmula para resolver equações do terceiro grau que ficou conhecida como Fórmula de Cardano embora se saiba que foi Tartaglia quem sugeriu a ele a solução para estas equações. Em seu livro Ars Magna Cardano apresentou o que se considera ser a primeira publicação do conceito de número complexo. Cardano fez a seguinte pergunta: Se alguém pede que você divida 10 em duas partes, que multiplicadas resultariam em 30 ou 40, é evidente que este problema não tem solução. Em seguida ele faz um comentário surpreendente: No entanto, resolveremos isto da seguinte maneira, … e prossegue encontrando as raízes \(5+\sqrt{-15}\) e \(5-\sqrt{-15}\) cuja soma é \(10.\) Neste ponto ele afirmou que, … colocando de lado a tortura mental envolvida, multiplicando as duas raízes temos 25 — (–15). Portanto o produto é 40. Apesar das descobertas de Cardano mais de dois séculos se passaram até que os números complexos fossem aceitos como entidades matemáticas legítimas. Durante este intervalo muitos autores se recusaram a usar tais estranhas entidades.
Em 1545 Gerônimo Cardano publicou uma fórmula para resolver equações do terceiro grau que ficou conhecida como Fórmula de Cardano embora se saiba que foi Tartaglia quem sugeriu a ele a solução para estas equações. Em seu livro Ars Magna Cardano apresentou o que se considera ser a primeira publicação do conceito de número complexo. Cardano fez a seguinte pergunta: Se alguém pede que você divida 10 em duas partes, que multiplicadas resultariam em 30 ou 40, é evidente que este problema não tem solução. Em seguida ele faz um comentário surpreendente: No entanto, resolveremos isto da seguinte maneira, … e prossegue encontrando as raízes \(5+\sqrt{-15}\) e \(5-\sqrt{-15}\) cuja soma é \(10.\) Neste ponto ele afirmou que, … colocando de lado a tortura mental envolvida, multiplicando as duas raízes temos 25 — (–15). Portanto o produto é 40. Apesar das descobertas de Cardano mais de dois séculos se passaram até que os números complexos fossem aceitos como entidades matemáticas legítimas. Durante este intervalo muitos autores se recusaram a usar tais estranhas entidades.